


Three realistic predictions on how we'll use generative AI models over the next three years
I'm tired of reading click-bait articles about how "AI will change everyone's life". In this post, I share my realistic predictions of how I think LLMs will actually change in the next few years.

The LLM hype
Not too long ago, a wonderous tool called ChatGPT quickly became a hit success overnight. Since then, the media and world have been taken by storm by how AI is going to change everything. Specifically, I think most of them are referring to language models since that seems to be the most popular form of AI discussed in the news (although image generation is a close second).
Having worked in AI for a bit and seeing how these technologies are changing over the last few years, I wanted to give my take on how I think LLMs will actually change over the next few years.
Going forward, I’ll use the word “AI” as synonymous with “foundational models” in this article, since that’s the main type of AI that everyone seems to be talking about.
I have three goals with this post – let me know if you think I’ve actually achieved them:
No clickbaity exaggerations. I don’t want to hack clicks onto this article because I promise a rosy future where robots do your laundry and dishes. If you read this article, it should be because you found it interesting enough to send to a friend.
Be realistic about what’s imminent. Every future scenario I paint should be something you and hundreds of millions of others experience within the next three years.
Easy enough to explain to your grandma. I hate to pick on her, but if it’s not easy enough for your grandma to understand, I’ve made it too complicated.
Note: going by these goals, the PM in me is thinking that if I had a north-star metric, it would be number of readers who share this article with their grandmas. If you share it with your grandma, please let me know!
First things first
So, laid out at the beginning, here are my three realistic predictions of how we’ll use AI in the next few years:
AI will excel at analyzing and summarizing large stores of text (codebases, books, etc.), but you’ll still be limited to generating only small pieces of writing with AI.
Interacting with AI will be just like like interacting with another person rather than chatting with a chatbot.
AI models will know everything about you and naturally interact with the tools you use daily.
For each of these, I’m going to lay out the facts, show some data that supports the facts, and then paint a picture of what that’ll actually look like with examples.
AI for analyzing, but not so much for writing.
The prediction
AI will excel at analyzing and summarizing large stores of text (codebases, books, etc.), but you’ll still be limited to generating only small pieces of writing with AI.
The data
Two things matter for (generative) AI models: the context window and the max output token limit. Said simply: context window = input (what goes into the model) + output tokens (what the model responds with).
The simple fact is that, as they get better, AI models can handle bigger context windows. However, the output tends to become random and useless after a certain length. In other words, the practical input windows of new models are growing much faster than the output windows.1
The latest and greatest models from Google can handle up to 2m tokens (3k pages of text or 250k LOC). Other models in the works in the research stages can handle up to 10m tokens (15k pages of text or 1.25m LOC). But those same models are limited to only ~8000 tokens of output – around 125 pages. That’s a 244x smaller output window than input – and that’s the absolute cutting edge with the best models.
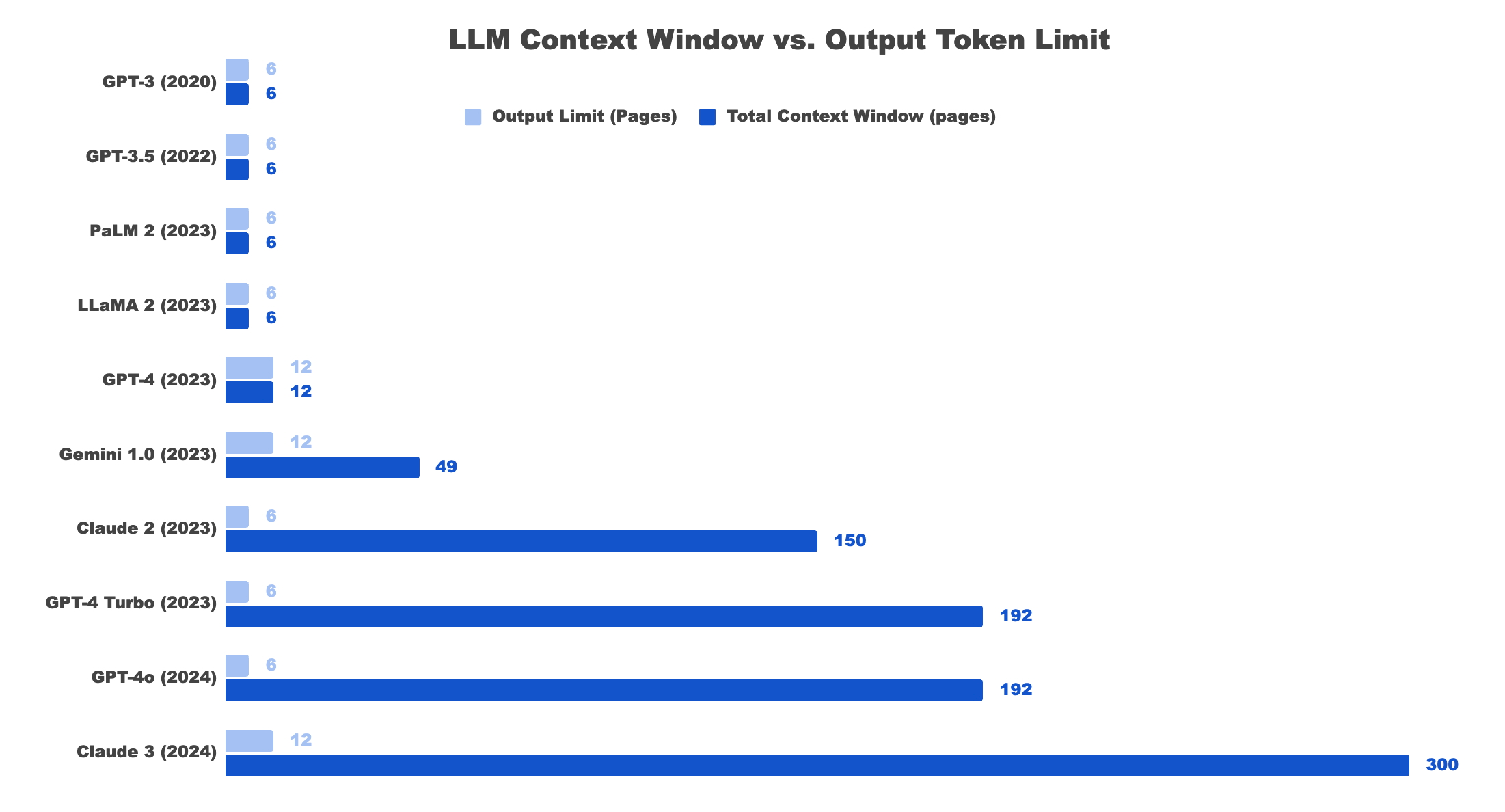
Even OpenAI only just launched an alpha program for long-context GPT-4o, with just a 64k output token window (1k pages of text or around 8k LOC). The trend of output windows being orders of magnitude smaller than input windows will remain true as models get more advanced.
The implications
Because of the discrepancy between input vs output windows, AI will excel at summary and analysis style tasks rather than generation tasks.
For example, here are some realistic scenarios we can expect within the next three years within the software engineering space:
LLMs will be able to read entire codebases and suggest improvements, optimizations, security vulnerabilities, etc.
LLMs will be able to write a single file in a codebase while considering the architecture, style, and nuances of the rest of the codebase.
Large codebases will still need engineers to architect, write, and maintain them.
This can be mapped to other industries:
Researchers will be able to analyze hundreds or thousands of published papers on a topic and relate them to a study they’re conducting, but they should still expect to write the research papers themselves.
Lawyers can analyze hundreds of briefs, precedents, and legal proceedings, but still will need to write their own contracts.
Knowledge workers can search across everything within their company to get a useful answer but still need to write their documents (although hopefully not emails!)
Human or chatbot? We may never know.
Interacting with AI will be just like like interacting with another person rather than chatting with a chatbot.
The data
The latest AI models are multimodal, meaning they can take in text, audio, image, and video input. Furthermore, model output latency for audio is going down from a few seconds to a few hundred milliseconds – on par with normal human conversation.
The latest multimodal LLM, GPT-4o, can process text, audio, video, and images in real-time. The “o” in the name actually stands for “omni” as in “omniIn addition, it can also return audio output back with an average of 320ms latency, down from about 3 seconds in prior models, since it’s built from the ground up to support audio input/output. The demos are truly incredible.
Not to be forgotten, Google’s Gemini Live allows you to interact in real-time using video, audio, and text and get low-latency responses.
These models are also able to make sense of images and videos, giving them the ability to answer requests like “Help me understand this code I’m looking at” or “What does this paragraph mean?” – they’ll automatically see what you see and interpret it as another human would.
The implications
This model of interacting is identical to how humans interact. Because humans assume other humans have the same ability to see, hear, and reason, we use lots of shortcuts in our speech that primitive models can’t handle.
Consider the simple example: “What does this line in the code mean?” There are several problems with this for AI models:
They don’t know what “this” line is – they can’t see what you’re seeing!
Understanding how to interpret “mean” requires context on what you know – are you a lawyer or a software engineer? If I’m explaining a line of code to an engineer, I’ll use wildly different terminology and give less context than if I’m explaining to a lawyer.
Here are some realistic scenarios I expect will happen in the next three years:
In your pocket, you’ll have a translator who knows every language, a Mike Ross lawyer who knows everything about law, the best engineer to pair program with, and so much more. And you’ll be able to talk with them on the phone as if they were a real human helping you out.
Some people will wear glasses that analyze everything they’re looking at and provide useful information about whatever they see. They’ll be able to ask questions like “What is this plant I’m looking at?” or “I don’t remember this person’s name – what is it?” and get correct answers.
Know thyself, wield thine tools.
The prediction
AI models will know everything about you and naturally interact with the tools you use daily.
The data
Many popular techniques exist to enrich LLMs with information they weren’t trained on, resulting in higher quality and more specific output. The most popular method is called Retrieval Augmented Generation (RAG). Over the last few years, cloud companies have started providing RAG-as-a-service for other developers (Google Cloud, AWS, Azure).
And many models today allow for function calling, which lets them interact with your day-to-day tools like calendar and email without additional work. OpenAI and Google Gemini already allow for function calling through their APIs.
But the real magic will be unlocked when the companies that make the technology we use daily, like our phones, start combining AI with all the information they already have about us.
Apple and Google are diving deep into incorporating AI into their phones and combining it with the treasure trove of data they have about the user to allow AI models to perform seemingly magical things for us.
The implications
Apple Intelligence, built into the upcoming iPhone 16 models, will allow you to say things like, “What time is my mom’s flight landing?” From this seemingly simple query, it’ll do a couple of things:
Look up which contact is your mom
Look at the exchanges of texts between you and your mom
See the flight number that she sent to you
Pull up the latest flight information from online
All of this happens in seconds, and out comes your response, just as if you had asked another person who knows everything about your life.
And Google’s latest Gemini assistant built into Android and their Pixel line of phones will perform similar tasks. For example, you’ll be able to ask, “What’s my Airbnb address again?” and it’ll do the following:
See that you just arrived in Greece
Look through your email
Find an Airbnb email confirmation for Greece
Extract the address from the email
And on the other hand, these models will also be able to interact with your tools using function calling. Here are some example queries that will work seamlessly:
Put my mom’s flight tomorrow into my calendar
Forward the Airbnb confirmation email to my wife
Reminder me to get all the groceries that Joanna texted me about when I get to the grocery store
The net effect is that models can get all relevant information about you (via RAG) and also interact with your day-to-day tools (via function calling).
It’ll feel like having a personalized model at your fingertips that’s aware of all relevant information concerning you and can interact with your calendar, email, etc.
In summary
In a few years, we’ll all have the world’s most attentive and capable executive assistant within our pocket – and that’s just the beginning.
I hope reading this has built some (justified!) excitement about all the amazing things that will happen to AI models over the next few years.
If you enjoyed reading this article and want more non-clickbaity content in your emails, throw me a subscribe.
And if you found this article easy to understand and want to share it with your grandmother as I mentioned at the beginning, go ahead.
Why does this discrepancy exist? Well, it’s because increasing the size of input context windows depends on the sizes of the training data, whereas increasing the output context window size requires additional computation power for each generation since the model has to use all previous tokens in each output to predict the next token of output.